Kubernetes Service & Service Discovery
💡 Service
- 노드의 파드는 기본적으로 외부통신이 안되는 내부망의 환경에 있다
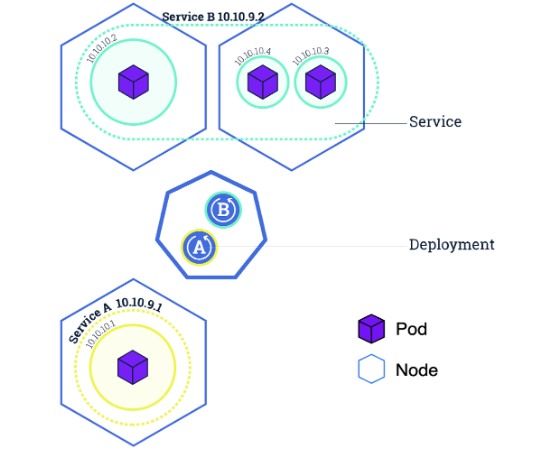
- Service란 Pod의 논리적 집합이며 어떻게 접근할지에 대한 정책을 정의해놓은 것
- Service는 기본적으로 Load Balancing 과 Port Forwarding 기능을 포함한다
- Label Selector를 통해 노출시킬 오브젝트의 레이블을 지정하는 방식이 주로 쓰인다
- 외부에 노출시킬때 4가지 타입이 있다
- ClusterIP (default) - 클러스터 내부 통신용
- NodePort - 노드IP:Port 의 방식을 통해 외부에서 접근 (NAT), 30000번대 포트
- Load Balancer - 외부의 Load Balancer를 사용하는 방법
- ExternalName - kube-dns로 DNS를 이용하는 방법
💡 Service Discovery
- MSA와 같은 분산 환경은 서비스 간의 원격 호출로 구성이 되며, 원격 서비스 호출은 IP와 포트를 이용하는 방식이 있다
- 클라우드 환경으로 바뀌면서 서비스가 오토 스케일링 등에 의해 동적으로 생성되거나
컨테이너 기반의 배포로 인해 서비스의 IP가 동적으로 변경되는 일이 잦아졌다 - 이때, 서비스의 위치를 알아낼 수 있는 기능이 Service Discovery이다
다음 그림을 보자
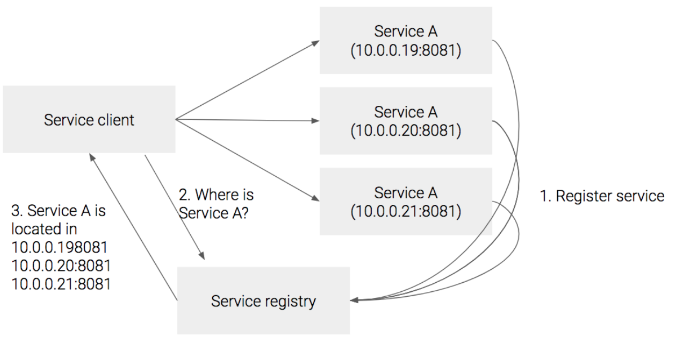
- Service A의 인스턴스들이 생성될때, Service A에 대한 주소를 Service Registry에 등록한다
- Service A를 호출하고자 하면 Registry에 A의 주소를 물어보고 등록된 주소를 받아서 그 주소를 호출한다
Service Registry를 구현하는 방법
- 가장 쉬운 방법은 DNS 레코드에서 하나의 호스트명에 여러개의 IP를 매핑시키는것이다
하지만 이 방법은 레코드 삭제시 업데이트 되는 시간 등이 소요되기 떄문에 적절한 방법은 아니다 - 다른 방법으로는 솔루션을 사용하는 방법인데,
ZooKeeper나 etcd와 같은 서비스를 이용할 수 있고 Netflix의 Eureka나 Hashcorp의 Consul과 같은 서비스가 있다
Service Discovery의 종류
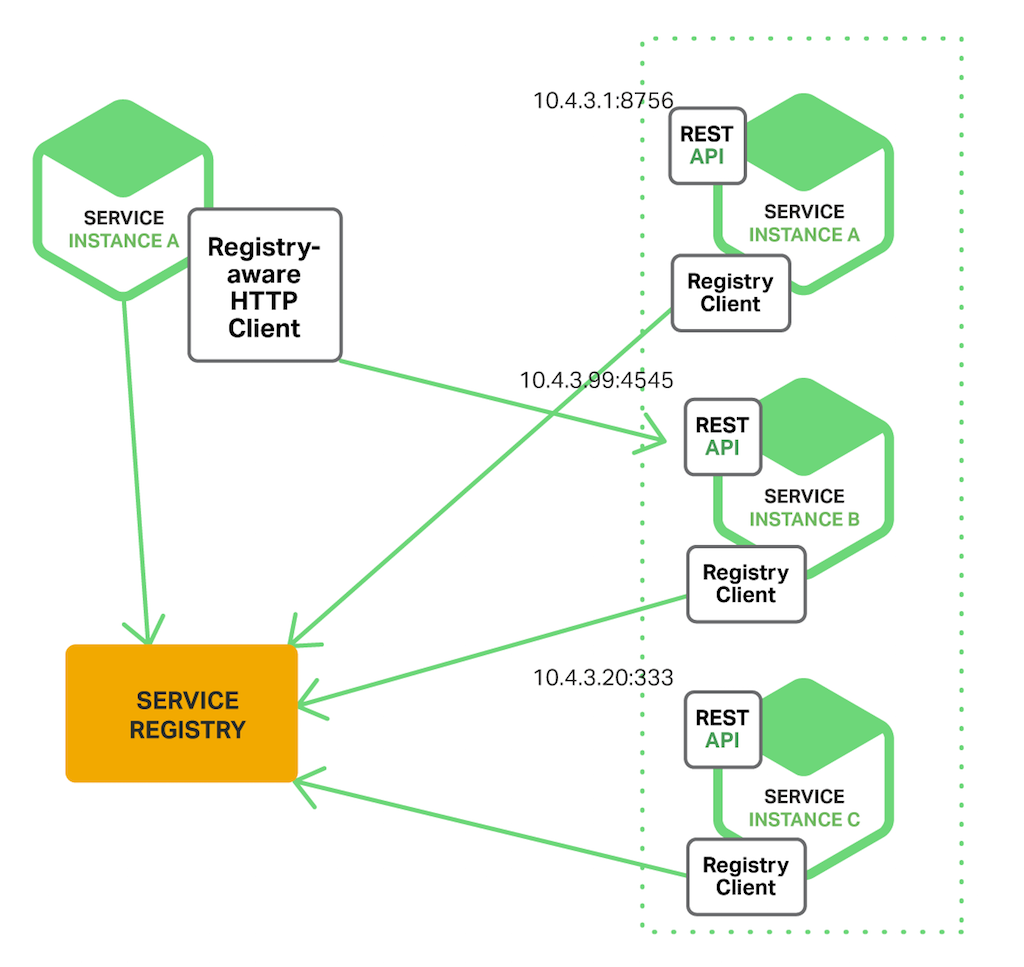
Client Side Discovery
 https://mangchhe.github.io/springcloud/2021/04/07/ServiceDiscoveryConcept/
https://mangchhe.github.io/springcloud/2021/04/07/ServiceDiscoveryConcept/
생성된 서비스는 Service Registry에 서비스를 등록하고, 서비스를 사용할 클라이언트는 Service Registry에서 서비스의 위치를 찾아 호출하는 방식이다.
장점
- 구현이 비교적 간단
- 클라이언트가 사용 가능한 서비스 인스턴스에 대해 알고있기 때문에 각 서비스별 로드 밸런싱 방법을 선택할 수 있다.
단점
- 클라이언트와 서비스 레지스트리가 연결되어 있어서 종속적이다.
- 서비스 클라이언트에서 사용하는 각 프로그래밍 언어 및 프레임워크에 대해서 클라이언트 측 서비스 검색 로직을 구현해야 한다.
대표적으로 Netflix OSS(Netflix Open Source Software)에서 Client-Side discovery Pattern을 제공하는 Netflix Eureka가 Service Registry 역할을 하는 OSS이다.
Server Side Discovery
https://mangchhe.github.io/springcloud/2021/04/07/ServiceDiscoveryConcept/
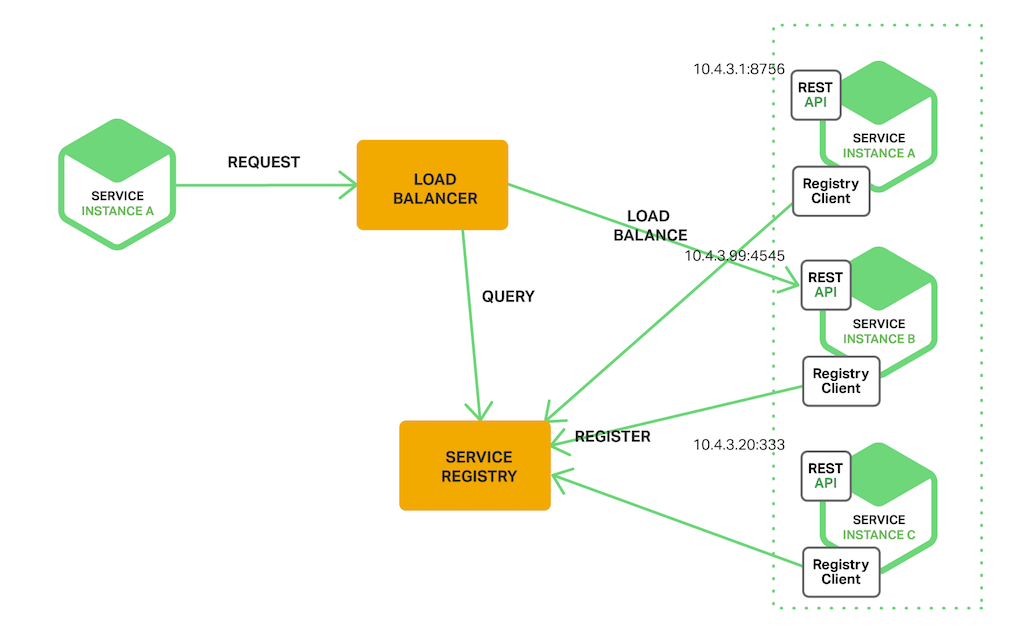
서비스를 사용할 클라이언트와 Service Registry 사이에 일종의 Proxy 서버인 Load Balancer를 두는 방식이다.
클라이언트는 Load Balancer에 서비스를 요청하고 Load Balancer가 Service Registry에 호출할 서비스의 위치를 질의하는 방식이다.
장점
- discovery의 세부 사항이 클라이언트로부터 분리되어있다(의존성↓)
- 분리되어 있어 클라이언트는 단순히 로드 밸런서에 요청만 한다. 따라서 각 프로그래밍 언어 및 프레임 워크에 대한 검색 로직을 구현할 필요가 없다
- 일부 배포환경에서는 이 기능을 무료로 제공한다.
단점
- 로드밸런서가 배포환경에서 제공되어야 한다.
- 제공되어있지 않다면 설정 및 관리해야하는 또 다른 고 가용성 시스템 구성 요소가 된다
AWS의 ELB나 GCP의 로드밸런서가 대표적이다.
Kubernetes에서의 Service Discovery
DNS를 이용하는 방법서비스는 생성되면 [서비스 명].[네임스페이스 명].svc.cluster.local 이라는 DNS 명으로 쿠버네티스 내부 DNS에 등록된다. 쿠버네티스 클러스터 내부에서는 이 DNS 명으로 서비스에 접근이 가능한데, 이때 DNS에서 리턴해주는 IP는 외부IP(External IP)가 아니라 ClusterIP이다.
External IP를 명시적으로 지정하는 방법
다른 방식으로는 외부 IP를 명시적으로 지정하는 방식이 있다. 쿠버네티스 클러스터에서는 이 외부IP를 별도로 관리하지 않기 때문에, 이 IP는 외부에서 명시적으로 관리되어야 한다.
apiVersion: v1
kind: Service
metadata:
name: hello-node-svc
spec:
selector:
app: hello-node
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
externalIPs:
- 80.11.12.11AWS, GCP가 제공하는 Load Balancer를 이용하는 방법
퍼블릭 클라우드의 경우에는 이 방식보다는 클라우드 내의 로드밸런서를 붙이는 방법을 사용한다.
서비스에 정적 IP를 지정하기 위해서는 우선 정적 IP를 생성해야 한다.
VPC 메뉴의 External IP 메뉴에서 생성해도 되고 CLI 명령줄을 이용해 생성해도 된다.
apiVersion: v1
kind: Service
metadata:
name: hello-node-svc
spec:
selector:
app: hello-node
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
type: LoadBalancer
loadBalancerIP: 생성한 정적 IP