
📘 처리량 최적화 - 개념
이번에는 성능 정의 중 2번째인 처리량에 대해 알아보겠습니다.
처리량이란 주어진 기간에 완성되는 작업의 수를 뜻합니다, 보통 처리량은 시간 단위 / 초 단위로 작업을 나눠 측정합니다.
- 처리량 향상을 위한 2가지 접근법
- Thread Pooling
📘 어플리케이션의 처리량 개선 방법
하나의 작업을 완수하는데 T의 시간이 걸리면 이룰수 있는 최소 처리량은 1/T 가 됩니다.
작업은 하위 Task로 나눌 수 있다면 T/N의 최대 처리량을 얻을 수 있습니다.
하지만, 하위 Task로 작업을 나누더라도 T/N 보다 낮은 처리량을 얻을 확률도 높습니다.
지연 시간을 최적화 할 때와 같은 단점을 가지고 있기 떄문입니다.
📕 1. 작업을 하위작업으로 나누기 (지연 시간을 최적화 할 때와 같은 단점)
- 작업을 여러개로 나누고, 나눈 작업을 스케줄링
- 완료한 각각의 작업을 다시 결합
- 이떄 컨텍스트 스위칭 등 리소스 비용 발생
- 무엇보다 처리량에 있어서 이 행동은 완전히 불필요한 행동임
📕 2. 각 작업을 별개의 스레드에 스케쥴링 (병렬 실행)
- 이 경우도 이론적으로 최대 처리량은 N/T 가 됨
- 이 접근법에서는 각 작업을 작은 Task로 나눠야 하는 전처리 과정이 필요 없음
- 작업은 각각 하나의 결과만 갖기 때문에, 작업의 포스트 프로세싱이 필요 없음
- 또, 완전히 별개의 작업이기 때문에 다른 작업의 완료를 위해 현재 작업이 Blocking 될 필요가 없음
- Thread-Pooling이나 Non-Blocking Queue 같은 기술의 의존 없이 최적의 처리량 달성 가능
📘 Thread Pooling
Thread Pooling은 Thread를 생성하고 나중의 작업을 위해 Thread를 다시 사용합니다.
매번 처음부터 다시 Thread를 생성하지 않아도 되는 이점이 있습니다.
Thread가 생성되면 Pool에 쌓이고, 작업이 대기열을 통해 스레드별로 분배되어 실행됩니다.
Runnable이 가능한 스레드는 대기열을 통해 작업을 할당 받습니다.
만약 모든 스레드가 Runnable 상태이면 대기열에서 대기하며, 작업중인 스레드가 Runnable 상태가 될 떄까지 대기합니다.
스레드를 바쁘게 사용하여, 작업들이 대기열에 쌓이게 되면 최대 처리량 / 리소스의 최대 사용률을 얻을 수 있습니다.
📕 Thread Pool 구현
- 낮은 오버헤드와 효율적인 대기열을 구현할 수 있습니다.
- JDK에서 지원하는 Fixed Thread Pool Executor를 사용 할 수 있습니다.
- 파라미터에 Pool에 존재할 스레드의 수를 지정항 생성합니다.
// 스레드 풀 생성
Executor executor = Executores.newFixedThreadPool(5);
// 스레드 실행
Runnable task = ...;
executor.execute(task);
📕 결론
2번쨰 접근법인 각 작업을 별개의 스레드에 스케쥴링 방법을 사용합니다.
각 작업은 독립적으로 실행되며 성능을 N(스레드/코어 수)으로 개선할 수 있습니다.
또, 스레드 풀을 이용해 일정 수의 스레드를 낮은 오버헤드로 유지시킬 수 있으며, 작업 시마다 스레드를 생성할 필요가 없습니다.
📘 처리량 최적화 - 구현 & 테스트
HTTP 어플리케이션을 예로 들어 HTTP 요청을 처리하는 스레드의 수를 상수로 갖기 위해 배운 것들을 활용합니다.
어플리케이션의 측정은 Apache Jmeter를 사용해 테스트 하고, 성능을 분석 / 측정 해보겠습니다.
📕 HTTP Server
- HTTP Request를 받는 HTTP Server를 만듭니다.
- 우선 HTTP Server가 Local Disk에서 아주 용량이 큰 책을 로딩합니다 (Tolstoy의 War and Peace)
- 어플리케이션은 Request Param으로 단어를 입력받아 책에서 해당 단어를 찾습니다. (ex: http://localhost:8080/search?word=talk)
- 책에서 단어의 개수를 세고, 클라이언트에세 단어의 개수를 전송합니다.
public class HTTPThroughputServer {
private static final String INPUT_FILE = "throughput/war_and_peace.txt";
private static final int NUMBER_OF_THREAD = 1;
public static void main(String[] args) throws IOException {
Resource bookResource = new ClassPathResource(INPUT_FILE);
String bookText = new String(Files.readAllBytes(Paths.get(bookResource.getURI())));
startServer(bookText);
}
/* Create & Start HTTP Server */
public static void startServer(String text) throws IOException {
HttpServer server = HttpServer.create(new InetSocketAddress(8080), 0);
server.createContext("/search", new WordCountHandler(text));
Executor executor = Executors.newFixedThreadPool(NUMBER_OF_THREAD);
server.setExecutor(executor);
server.start();
}
/* HTTP Request Handler */
@AllArgsConstructor
private static class WordCountHandler implements HttpHandler {
private String text;
@Override
public void handle(HttpExchange exchange) throws IOException {
String query = exchange.getRequestURI().getQuery(); // word=xxxx
String[] keyValue = query.split("="); // word / xxxx
String action = keyValue[0]; // word
String word = keyValue[1]; // xxxx
// Request Param의 Key가 word가 아니면 400 Error
if (!action.equals("word")) {
exchange.sendResponseHeaders(400, 0);
return;
}
long count = countWord(word);
// Response를 주고 OutputStream을 닫아줌
byte[] response = Long.toString(count).getBytes();
exchange.sendResponseHeaders(200, response.length);
OutputStream outputStream = exchange.getResponseBody();
outputStream.write(response);
outputStream.close();
}
/* 책에서 나오는 단어의 개수를 세는 함수 */
private long countWord(String word) {
long count = 0;
int index = 0;
while (index >= 0) {
index = text.indexOf(word, index);
// index가 양수면 단어를 찾은 것임
if (index >= 0) {
count++;
index++;
}
}
// index가 음수면 더이상 찾을 단어가 없으니 count를 반환하면서 return
return count;
}
}
}클래스를 실행하고 http://localhost:8080/search?word=talk를 브라우저에 입력하면 550개가 나옵니다.
다른 단어나 글자를 입력해도 카운팅된 숫자가 잘 나오고 있습니다.
이제 이 어플리케이션의 처리량 측정을 위해 Apache Jmeter를 이용해 테스트 계획을 세워 보겠습니다.
📘 Apache Jmeter를 이용한 어플리케이션 처리량 측정
Apache Jmeter는 Java 코드를 사용하지 않고 자동화된 성능 테스트 계획을 생성할 수 있습니다.
📕 테스트 계획의 첫번째
단어 리스트를 포함한 파일을 로딩하는 것으로, 각 단어에 HTTP 요청을 전송하고 응답을 기다립니다.
acceptable
accessible
accidental
accurate
acid
acidic
acoustic
acrid
actually
... 등등등 단어 리스트 CSV 파일- ex)
http://localhost:8080/search?word=word1 - ex)
http://localhost:8080/search?word=word2 - ex)
http://localhost:8080/search?word=word3
📕 테스트 계획의 두번째
서버는 가능한 한 빨리, 많은 Response를 전송합니다.
그리고 마지막엔 전송된 요청 수 / 응답을 받는데 걸린 시간 으로 나눠서 어플리케이션의 처리량을 알려줍니다.
📕 Jmeter 설정
- Test Plan 이름 설정
- Test Plan 우클릭 - Add - Threads - Thread Group 생성 (HTTP Server에 요청을 전송할 스레드 그룹)
- Thread 수 = 200,
- Thread Group 우클릭 - Add - Logic Controller - While Controller (입력 단어 반복 작업)
- While Controller 우클릭 - Add - Config Element - CSV Data Set Config (미리 준비된 search_words.csv 파일 로딩)
- CSV Data Set Config - Variable Names = WORD (While Loop 반복 작업에 사용할 새로운 단어)
- CSV Data Set Config - Delimiter =
\n으로수정 - CSV Data Set Config - Stop Thread On EOF =
True로 설정 (파일을 하나씩 읽게 하기 위함) - 이제 변수에 각 단어를 저장했으니 While Loop에 조건을 생성할 수 있습니다.
- While Controller - Condition 부분에
${___jexl3("${WORD}" != "<EOF>")}입력
이제 반복할 때마다 파일에서 단어를 읽고 단어 변수에 저장 후, HTTP 요청을 HTTP 서버 어플리케이션에 전송해,
읽은 단어가 책에 몇번 나타났는지 물어봅니다.
- While Controller - Add - Sampler - HTTP Request 추가
- HTTP Request Endpoint(Path) =
/search?word=${WORD}, 서버 IP, Port등 설정
마지막으로 실행된 테스트 결과를 요약할 Listener와 디버깅 목적의 View Results Tree도 추가 해줍니다..
- While Controller - Add - Listener - Summary Report
- While Controller - Add - Listener - View Results Tree
📕 Jmeter 실행
Jmeter를 실행하고 다른 스레드 풀 크기로 어플리케이션의 처리량을 측정합니다.
크기는 1부터 시작하겠습니다.
Sumarry Report 탭에서 Ctrl + R을 눌러 테스트를 실행 시켜보면 아까 설정한 어플리케이션 내부 스레드 풀의 크기 1로
초당 3~4000개의 요청을 처리하는 걸 볼 수 있습니다.
Summary Report

위 사진에서 Error 율이 발생한 이유는 HTTP Server를 나중에 실행했기 떄문에 생긴것 이므로 무시해도 됩니다.
📘 Application 처리량 측정 결과
이제 View Result Tree로 가서 요청과 응답 값을 확인 해봅시다.
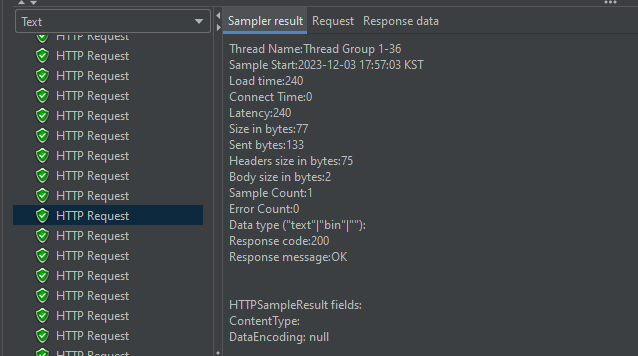
📕 Result
Result 부분에 헤더와 메타 데이터 정보들이 나오고 HTTP Request 200 OK 가 떠있습니다.
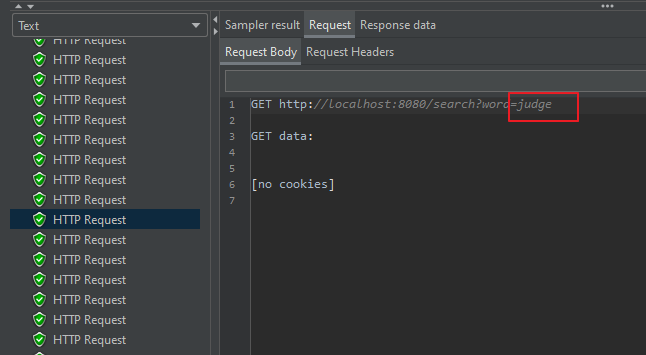
📕 Request
검색 단어는 judge가 들어가 있습니다.
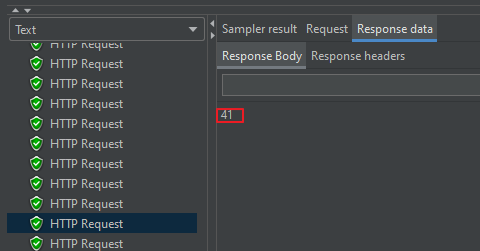
📕 Response
응답에는 책에 judge라는 단어가 41번 나온걸 볼 수 있습니다.
📕 결론
HTTP Server의 Thread Pool 크기를 물리 코어의 수 만큼 점점 늘려갈 수록 처리량도 급격히 늘어납니다.
그리고 가상 코어의 수까지 스레드를 더 추가하면 조금 이지만 그래도 처리량의 증가를 볼 수 있고,
가상 코어의 수 이상으로 스레드를 늘리면 처리량은 더이상 오르지 않습니다.
지연 시간 최적화를 할떄 작업을 완료한 하위 Task 들을 모두 결합할떄 발생하던 스위칭 비용 & 오버헤드가,
처리량 개선 작업에서는 오버헤드를 최소화 했기 떄문에 지연 시간 최적화에 비해 급격한 처리량 성능의 증가를 볼 수 있었습니다.
'📘 Backend > Concurrency' 카테고리의 다른 글
| Thread 간 Resource 공유 시 발생할 수 있는 문제 (3) | 2024.01.06 |
|---|---|
| ReentrantLock을 이용한 Thread 동기화 (2) | 2023.12.26 |
| Image Processing - Latency Optimization (지연시간 최적화) (0) | 2023.12.03 |
| Thread Blocking (Count Down Latch) (1) | 2023.11.28 |
| Thread.join()을 이용한 Thread 실행 순서 제어 (Race Condition) (6) | 2023.10.02 |